Choosing the Right Optimization or Retrieval Strategy for Large Language Models
Introduction
Modern Large Language Models (LLMs) are increasingly central to AI systems — powering everything from enterprise chatbots to multimodal assistants and autonomous agents. However, running, fine-tuning, and maintaining these massive models can be resource-intensive and expensive, especially for European startups, research institutes, and SMEs operating under strict data privacy (GDPR) or EU AI Act constraints.
That’s where LoRA, QLoRA, and RAG come in — three strategies that allow developers to optimize model performance, reduce compute cost, and improve contextual understanding without retraining full models.
In this post, we’ll explore:
-
What LoRA, QLoRA, and RAG actually are
-
When to use LoRA or QLoRA (parameter-efficient fine-tuning)
-
When to use RAG (retrieval-augmented generation)
-
How they complement each other in real-world AI architectures
-
Practical use cases across Europe and Belgium
1. Understanding LoRA and QLoRA
1.1 What is LoRA (Low-Rank Adaptation)?
LoRA stands for Low-Rank Adaptation of Large Language Models — a technique that allows fine-tuning a pre-trained model without updating all of its parameters.
Instead of retraining billions of parameters, LoRA inserts trainable low-rank matrices into specific layers (typically attention or feed-forward layers). This drastically reduces the number of trainable parameters — often by up to 99% — while preserving model quality.
Key Benefits of LoRA:
-
Parameter efficiency: Only a small number of weights are fine-tuned.
-
Faster training: 10–100× faster than full fine-tuning.
-
Less GPU memory: You can fine-tune 13B+ models on a single GPU.
-
Easy modularity: Add or remove LoRA “adapters” for domain-specific tasks.
-
Regulatory flexibility: Keeps the base model frozen, reducing data leakage risks.
1.2 What is QLoRA (Quantized LoRA)?
QLoRA builds on LoRA by introducing quantization — compressing model weights into lower precision formats (like 4-bit).
This enables fine-tuning very large models such as LLaMA-2 70B or Falcon 40B on consumer GPUs or mid-range servers, without significant performance degradation.
Key Benefits of QLoRA:
-
Extreme memory efficiency (fine-tune 70B model on a 48GB GPU)
-
Same accuracy as full precision LoRA
-
Cost-effective for research labs & SMEs
-
Easy deployment with Hugging Face’s PEFT + bitsandbytes libraries
Example stack:
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype="float16")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-hf", quantization_config=bnb_config)
lora_config = LoraConfig(r=8, lora_alpha=16, target_modules=["q_proj","v_proj"], lora_dropout=0.05)
model = get_peft_model(model, lora_config)
2. Understanding RAG (Retrieval-Augmented Generation)
RAG is not about fine-tuning the model itself — instead, it retrieves external knowledge at query time to augment the model’s context window.
In essence, RAG = LLM + Vector Database + Retriever.
How it Works:
-
A user query is converted into an embedding vector.
-
A retriever searches a vector database (like FAISS, Chroma, Weaviate, or Qdrant) for the most relevant documents.
-
The top matches are added to the prompt context.
-
The LLM generates an answer grounded in retrieved data.
This is ideal when:
-
You need fresh, domain-specific data (financial reports, legal documents, medical records).
-
You can’t or don’t want to fine-tune the model.
-
Data is frequently updated (news, knowledge bases).
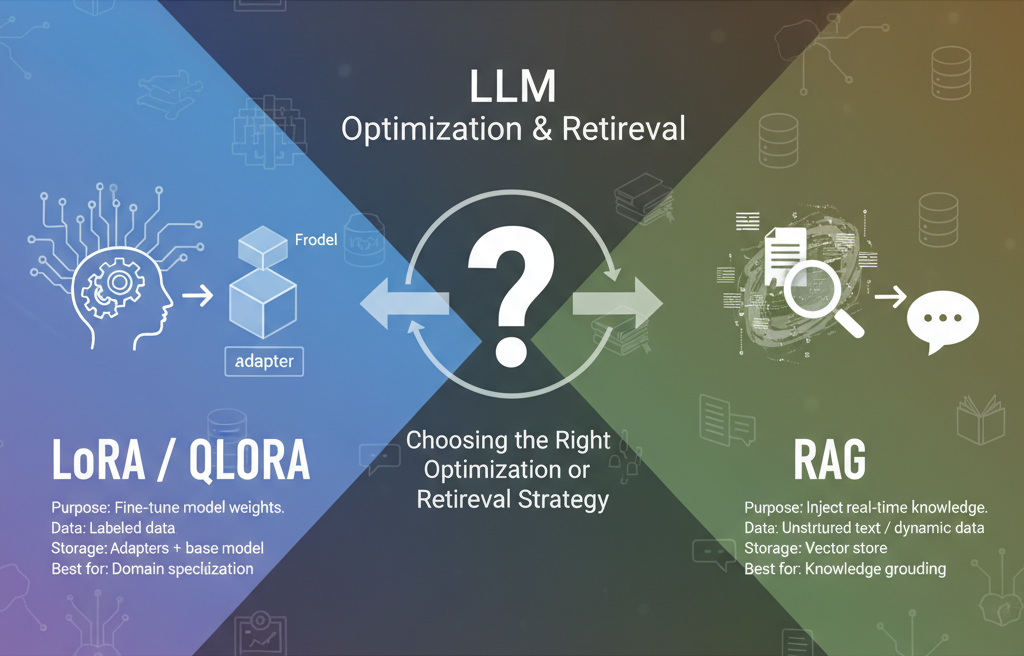
3. LoRA vs RAG: Choosing the Right Approach
| Feature | LoRA / QLoRA | RAG |
|---|---|---|
| Purpose | Fine-tune the model’s weights for new behavior or domain | Inject real-time knowledge into model outputs |
| Data type | High-quality labeled data (for tasks like classification, summarization, translation) | Large unstructured text corpora or dynamic data |
| Storage | Adapters + base model | Vector store (FAISS, Qdrant, Weaviate) |
| Update frequency | Rare (when new domain knowledge arises) | Frequent (whenever new data is added) |
| Compute cost | Low (fine-tune once) | Low-medium (runtime retrieval) |
| Regulatory compliance | Keeps base model frozen (GDPR-friendly) | Keeps data external (compliant with data locality rules) |
| Best for | Domain specialization | Knowledge grounding |
4. When to Use LoRA / QLoRA
You should choose LoRA or QLoRA when:
-
You need custom behavior: e.g., medical report summarization, legal reasoning, or manufacturing-specific instructions.
-
You want the model to understand domain language (Belgian legal terms, EU tax codes, technical manuals).
-
You have moderate labeled data for supervised fine-tuning.
-
You need lightweight, reusable adapters per customer or department.
Example Use Cases:
-
Healthcare (Belgium): Fine-tuning LLaMA-3 with LoRA adapters to interpret lab reports while ensuring privacy.
-
Finance (Europe): Adapting open models for multilingual financial summarization.
-
Customer Support: Fine-tuning support bots per company or region.
-
Industrial AI: Adapting control language for IoT or factory systems in Ghent, Antwerp, or Liège.
5. When to Use RAG
RAG is ideal when:
-
The data is constantly changing — such as product catalogs, legal updates, or market feeds.
-
You need traceable answers (cite sources).
-
You don’t want to fine-tune (e.g., for proprietary or confidential data).
-
The LLM should reference external knowledge (not memorize it).
Example Use Cases:
-
EU LegalTech: Build a GDPR-compliant assistant that retrieves real EU law articles.
-
Education: RAG bots trained on university course material, allowing real-time updates.
-
Enterprise Knowledge Bases: Corporate intranet search assistants.
-
Healthcare: Retrieve up-to-date clinical guidelines without retraining models.
6. Combining LoRA and RAG for Maximum Efficiency
In practice, the most powerful LLM applications combine both:
-
Use LoRA / QLoRA to teach the model domain logic and tone.
-
Use RAG to inject fresh or customer-specific data.
Example Architecture:
User → Query → Retriever (FAISS) → RAG Context
↓
LoRA-fine-tuned Model → Answer Generation
This hybrid setup allows you to:
-
Keep factual accuracy (via RAG)
-
Maintain specialized reasoning (via LoRA adapters)
-
Reduce overall cost while maximizing compliance
7. EU & Belgium-Specific Context
In Europe, where data protection, compute costs, and AI sovereignty are critical, LoRA/QLoRA and RAG align with strategic objectives:
-
Data locality: fine-tune with local data without sharing base models.
-
Green AI goals: LoRA/QLoRA reduce carbon footprint by cutting GPU hours.
-
Open-source compliance: build with Hugging Face, LangChain, and EU-hosted vector DBs.
-
Language diversity: fine-tune multilingual LoRA adapters for Dutch, French, and Flemish.
8. Implementation Stack (Recommended Tools)
| Category | Recommended Tools |
|---|---|
| LoRA / QLoRA | Hugging Face Transformers, PEFT, bitsandbytes |
| RAG | LangChain, LlamaIndex, Qdrant, Weaviate |
| Embeddings | OpenAI, Mistral, Cohere, or local models |
| Frameworks | FastAPI, Django, Streamlit for interfaces |
| Deployment | Docker, NVIDIA Triton, Hugging Face Spaces |
| Agents / Orchestration | LangGraph, n8n, OpenDevin, CrewAI |
9. Example Workflow
flowchart LR
A[Raw Documents] -->|Embed| B[Vector DB (FAISS / Qdrant)]
C[Query] --> D[Retriever]
D --> E[RAG Context]
E --> F[LoRA/QLoRA Fine-Tuned LLM]
F --> G[Response Generation]
This pipeline shows how retrieval (RAG) augments a fine-tuned model (LoRA) for context-aware, domain-specific, and up-to-date answers.
10. Conclusion
Both LoRA/QLoRA and RAG are essential pillars in the next generation of cost-efficient, privacy-conscious, and high-performance AI systems — especially for Europe’s fast-growing AI landscape.
-
Use LoRA / QLoRA when you want to teach your model new behavior or domain expertise.
-
Use RAG when you want your model to access fresh data and remain factually grounded.
-
Combine both for the best of both worlds — a smart, efficient, and GDPR-compliant AI assistant.
If your organization in Belgium or Europe is planning to build or optimize AI-powered applications using LoRA, QLoRA, or RAG, our team can help you design the architecture, fine-tune models, and deploy scalable solutions.
Contact us for a custom AI development quote or consultation today.