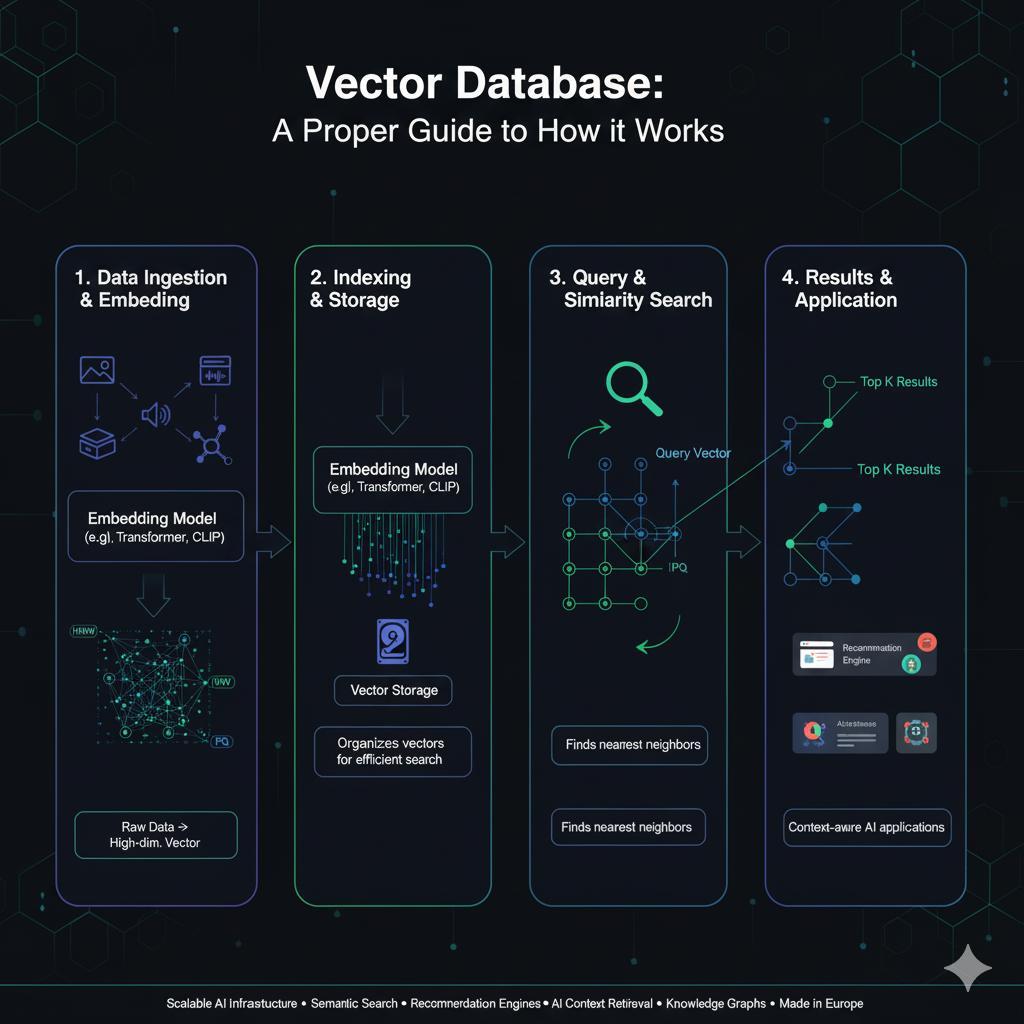
How a Handful of Lines Can Hijack Any LLM — The Poisoning Threat You’re Ignoring
Imagine shipping a new assistant to your customers that performs perfectly on every validation test — until, one day, a user types a seemingly meaningless phrase and the assistant issues dangerous, incorrect, or malicious instructions. You search the logs; nothing obvious.